
Qwen 团队最近发布了一款统一多模态大模型 Qwen2.5-Omni,开放了 7B 版本的权重。能够同时处理文本、图像、音频和视频输入,并以流式方式生成文本和语音响应。下面来详细看下:
开源地址:
- 论文地址:https://arxiv.org/abs/2503.20215
- 博客地址:https://qwenlm.github.io/zh/blog/qwen2.5-omni/
- GitHub 地址:https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
体验地址:
- 官方体验:https://chat.qwen.ai/
- Demo体验:https://modelscope.cn/studios/Q
研究动机:在日常生活中,人类能够同时感知视觉和听觉信息,并通过大脑处理这些信息后,以书写、说话或使用工具等方式进行反馈,从而与世界上的各种生物进行信息交流并展现智能。现有大模型多为单模态(如 LLM)或双模态(如 LVLM),缺乏统一的多模态实时交互能力,将听觉、视觉等不同模态与语言模型高效地统一起来,并以类似人类交流的方式(如同时提供文本和语音流式响应)进行输出,仍然是一个重大挑战。
开发统一且智能的全能模型(omni-model)需要仔细考虑几个关键因素。首先,必须设计一种系统性的方法,联合训练文本、图像、视频和音频等多种模态,以促进它们之间的相互增强。这种对齐对于视频内容尤为重要,因为需要同步音频和视觉信号的时间特征。其次,必须管理不同模态输出之间的潜在干扰,确保文本和语音标记等输出的训练过程不会相互干扰。最后,需要探索支持实时理解多模态信息并实现高效音频流输出的架构设计,从而降低初始延迟。
对于上述问题,阿里提出Qwen2.5-Omni,一个统一的多模态模型,能够同时处理文本、图像、音频和视频等多种模态,并以流式的方式同时生成文本和自然语音响应。
核心创新:
- 创新的时序对齐多模态RoPE(TMRoPE):提出了一种新颖的位置嵌入算法,通过将音频和视频帧以交错的方式组织,并显式地引入时间信息,实现了音频和视频的时序对齐,增强了多模态信息的融合。
- Thinker-Talker架构:设计了一种用于实时理解和语音生成的架构。其中,Thinker负责文本生成,Talker则利用Thinker的高级表示直接生成语音流,两者在训练和推理过程中均以端到端的方式联合进行,有效避免了不同模态输出之间的干扰。
- 流式处理与低延迟设计:通过采用块状处理方法对音频和视觉编码器进行改进,并引入滑动窗口的DiT模型,实现了音频和视频信息的流式处理,减少了初始包延迟,支持实时的多模态理解和语音生成。

下面来详细看下:
1、方法介绍
Thinker-Talker架构
Omni模型采用Thinker-Talker架构,这种架构的设计灵感来源于人类大脑和嘴巴的功能分工:Thinker(类似大脑)是一个Transformer解码器,配备了用于信息提取的音频和图像编码器,负责处理和理解来自文本、音频和视频模态的输入,并生成高层表征及相应的文本;而Talker(类似嘴巴)是一个双轨自回归Transformer解码器,其设计灵感来源于Mini-Omni,则负责将Thinker生成的高层表征和文本转化为语音输出。两者在训练和推理过程中均以端到端的方式联合进行,有效避免了不同模态输出之间的干扰。

感知(模态理解)
文本处理
使用Qwen分词器(基于字节级字节对编码,BPE),词汇表包含151,643个常规标记。文本被转换为一系列隐藏表征,用于后续的处理和生成。
音频处理
音频输入被重采样至16kHz,并转换为128通道的梅尔频谱图,窗口大小为25毫秒,跳跃长度为10毫秒。使用Qwen2-Audio的音频编码器,每帧音频表征对应原始音频信号中40毫秒的片段。下面是对这一过程的详细解读:
- 重采样至16kHz:音频输入被重采样至16kHz,采样率决定了音频信号在数字形式下的时间分辨率,16kHz是一个常见的采样率,能够较好地平衡计算效率和音频质量。通过重采样,可以确保不同来源的音频数据具有一致的时间分辨率,便于后续处理。
- 转换为128通道的梅尔频谱图:梅尔频谱图是一种将音频信号的频谱信息以梅尔频率尺度表示的特征图。梅尔频率尺度更接近人类听觉系统的感知方式,能够更好地反映音频信号中的重要频率信息。128通道意味着将音频信号的频谱划分为128个频带,每个频带对应一个通道,从而能够更细致地捕捉音频的频率特征。这种转换过程通常包括短时傅里叶变换(STFT)等步骤,将时域信号转换为频域信号,并在梅尔频率尺度上进行量化。
- 窗口大小为25毫秒,跳跃长度为10毫秒:在进行短时傅里叶变换时,窗口大小决定了每次分析音频信号的时间范围,而跳跃长度决定了相邻窗口之间的重叠程度。窗口大小为25毫秒意味着每次分析25毫秒内的音频信号,而跳跃长度为10毫秒则表示相邻窗口之间有15毫秒的重叠。这种设置能够在一定程度上平衡时间分辨率和频率分辨率,使得模型能够捕捉到音频信号中的短时变化和频率信息。
- 使用Qwen2-Audio的音频编码器:该编码器对转换后的梅尔频谱图进行进一步处理,提取音频的高级特征表示。每帧音频表征对应原始音频信号中40毫秒的片段,这意味着编码器将每40毫秒的音频信息压缩为一个特征向量。这种压缩过程能够保留音频的关键信息,同时减少数据量,便于模型进行高效的处理和理解。
图像和视频处理
使用Qwen2.5-VL的视觉编码器,基于Vision Transformer(ViT)模型,参数量约为6.75亿。视觉编码器采用混合训练策略,结合了图像和视频数据,确保其在图像理解和视频理解方面的熟练度。视频采用动态帧率采样,以适应音频采样率并尽可能完整地保留视频信息。
- 混合训练策略:视觉编码器采用混合训练策略,结合了图像和视频数据。这意味着编码器在训练过程中同时接触到静态图像和动态视频,从而能够学习到图像和视频中的共同特征和差异特征。这种混合训练策略有助于提高模型在图像理解和视频理解方面的熟练度,使其能够更好地处理多种视觉任务。
- 视频采用动态帧率采样:为了适应音频采样率(40毫秒每帧)并尽可能完整地保留视频信息,视频采用动态帧率采样。动态帧率采样意味着根据视频内容的实际时间长度和重要性,灵活调整视频的帧率。这样可以在保证音频和视频时间对齐的同时,避免因固定帧率导致的信息丢失或冗余。例如,在视频内容变化较快的部分,可以适当提高帧率以保留更多细节;而在内容变化较慢的部分,则可以降低帧率以减少冗余信息。
时间对齐多模态旋转位置嵌入(TMRoPE)

在多模态模型中,处理视频和音频输入时,需要考虑以下关键问题:
- 时间对齐:视频中的视觉信息和音频信息在时间上是同步的,因此需要一种方法来确保模型能够理解这种时间上的对齐关系。
- 位置信息:不同模态(文本、图像、音频)的位置信息需要被有效地编码,以便模型能够区分不同模态的输入并理解它们之间的关系。
- 动态帧率:视频的帧率可能不固定,因此需要一种灵活的方法来处理不同帧率的视频。
为了解决这些问题,本文提出了TMRoPE,这是一种结合了绝对时间位置的多模态旋转位置嵌入(M-RoPE)方法。
TMRoPE的核心思想是将多模态输入的3维位置信息(时间、高度、宽度)进行编码,并引入绝对时间位置信息。具体实现如下:
位置信息的分解
TMRoPE将原始的旋转位置嵌入(RoPE)分解为三个维度:时间维度:用于表示时间信息;高度维度:用于表示图像或视频帧中的垂直位置;宽度维度:用于表示图像或视频帧中的水平位置。
不同模态的位置编码
- 文本输入:时间、高度和宽度三个部分使用相同的位置ID,因此TMRoPE在功能上等同于一维旋转位置嵌入(1D-RoPE)。
- 音频输入:时间维度使用相同的位置ID,并引入绝对时间位置编码,每个时间ID对应40毫秒。
- 图像输入:时间ID保持不变,而高度和宽度部分根据标记在图像中的位置分配不同的ID。
- 视频输入:视频被视为一系列图像,每帧的时间ID递增,高度和宽度部分的ID分配方式与图像相同。由于视频的帧率不固定,作者根据每帧对应的实际时间动态调整帧间的时间ID,确保一个时间ID对应40毫秒。
多模态输入的位置编号
当模型输入包含多种模态时,每种模态的位置编号从前一种模态的最大位置ID加1开始初始化。这种初始化方式确保了不同模态的位置信息不会相互冲突,同时保留了它们之间的相对顺序。
时间交错方法
为了使模型能够同时接收视觉和听觉信息,作者提出了一种特殊设计,称为时间交错方法。具体步骤如下:
- 按时间分割:将视频中的表征按实际时间每2秒分割为一个块。
- 交错排列:在每个2秒的时间块内,将视觉表征放在前面,音频表征放在后面,从而实现视频和音频表征的交错排列。
这种设计使得模型能够在处理视频和音频输入时,更好地理解它们之间的时间对齐关系,同时保留了视觉和听觉信息的完整性。
生成
文本生成
文本生成由Thinker负责,其生成逻辑与广泛使用的大型语言模型(LLMs)基本相同。具体来说:
- 基于词汇表的概率分布:Thinker通过自回归采样生成文本。这意味着在生成每个词时,模型会基于之前生成的词序列来计算下一个词的概率分布。例如,假设已经生成了词序列“今天天气很”,模型会计算下一个词的概率分布,如“好”、“热”、“冷”等,并从中选择一个词继续生成。
- 重复惩罚(Repetition Penalty):为了避免生成重复的内容,模型可以使用重复惩罚技术。如果某个词在生成过程中已经出现过多次,模型会降低其再次出现的概率。例如,如果模型已经生成了“今天天气很好,今天天气很好”,重复惩罚会使得“今天”和“天气”等词的生成概率降低,从而减少重复。
- Top-p采样:为了增加生成文本的多样性,模型可以使用Top-p采样技术。这种方法不是直接选择概率最高的词,而是从概率最高的前p%的词中随机选择一个词。例如,假设模型计算出下一个词的概率分布后,选择概率最高的前10%的词(如“好”、“热”、“冷”等),然后从这10%的词中随机选择一个词继续生成。这可以避免模型总是生成相同的词,增加生成文本的多样性。
语音生成
语音生成由Talker负责,Talker接收来自Thinker的高层表征以及采样的文本标记嵌入。具体过程如下:
- 高维表征和离散采样标记的整合:Talker接收来自Thinker的高维表征,这些表征隐式地传递了文本的语义信息,包括语调和态度等。此外,Thinker的表征主要表达语义空间的相似性,而非语音相似性。由于语音信号的复杂性,即使语义相似的文本也可能对应多种不同的语音特征。离散采样标记通过提供明确的文本标记,帮助模型在生成语音时消除这种不确定性。
- 高效的语音编解码器:为了高效表示语音的关键信息,本文设计了一种名为quent-tts-tokenizer的编解码器。该编解码器能够高效表示语音的关键信息,并可通过因果音频解码器流式解码为语音。在接收信息后,Talker开始自回归生成音频标记和文本标记。语音生成不需要与文本在单词级别或时间戳级别对齐,这显著简化了训练数据和推理过程的要求。
关于离散采样标记的解读
离散采样标记(Discrete Sampling Tokens)的作用是提供明确的文本标记,帮助模型在生成语音时消除不确定性。以下是对这句话的详细解读:
1. 不确定性来源
在语音生成任务中,一个主要的挑战是文本内容和语音特征之间的映射关系并不是一一对应的。具体来说:
- 语义相似性:不同的单词或短语可能具有相似的语义,但它们的语音特征可能完全不同。例如,“cat”和“kitten”在语义上都与“猫”有关,但它们的发音差异很大。
- 语音多样性:即使是相同的文本内容,也可以用不同的语音特征来表达,例如不同的语调、语速、情感等。例如,“今天天气很好”这句话可以用欢快的语调说,也可以用平淡的语调说。
这种映射关系的多样性导致了生成语音时的不确定性。如果模型只依赖于语义信息(如高维表征),它可能无法准确地确定应该生成哪种语音特征。
2. 离散采样标记的作用
离散采样标记通过提供明确的文本标记,帮助模型在生成语音时消除这种不确定性。具体来说:
- 明确的文本标记:离散采样标记是将文本内容转换为一系列离散的符号(tokens),这些符号直接对应于文本中的单词或子词。例如,句子“今天天气很好”可以被标记化为[今天, 天气, 很, 好]。
- 消除不确定性:这些离散的标记为模型提供了明确的指导,告诉模型在生成语音时应该对应哪些具体的单词或短语。通过这种方式,模型可以更准确地选择与这些标记对应的语音特征,从而减少生成语音时的不确定性。
3. 明确的文本标记如何帮助模型
- 语义到语音的映射:离散采样标记帮助模型将语义信息(高维表征)与具体的语音特征联系起来。例如,如果模型知道当前生成的标记是“今天”,它可以根据这个标记选择与“今天”对应的语音特征。
- 减少歧义:离散采样标记减少了语音生成中的歧义。例如,如果模型只知道当前的语义是“猫”,它可能无法确定是生成“cat”还是“kitten”的语音。但如果它知道具体的标记是“cat”,它就可以准确地生成“cat”的语音。
- 支持流式生成:离散采样标记使得语音生成能够以流式的方式进行。模型可以根据当前生成的标记逐步生成语音信号,而不需要等待整个文本生成完成。这使得语音生成更加高效,能够实时响应用户的输入。
4. 具体例子
假设模型需要生成句子“今天天气很好”的语音。以下是离散采样标记如何帮助模型生成语音的过程:
- 文本标记化:输入文本:“今天天气很好”,标记化结果:[今天, 天气, 很, 好]
- 生成离散采样标记:Thinker生成的高维表征隐式地传递了语义信息,例如“今天”表示的是今天的日期,“天气”表示的是气象条件等。离散采样标记[今天, 天气, 很, 好]为模型提供了明确的文本信息。
- 语音生成:Talker接收高维表征和离散采样标记。对于每个标记,Talker根据高维表征和标记信息生成对应的语音特征。例如:
- “今天”对应语音特征[语音特征1]
- “天气”对应语音特征[语音特征2]
- “很”对应语音特征[语音特征3]
- “好”对应语音特征[语音特征4]
- 流式解码:Talker使用流式解码器逐步生成语音信号。每个语音特征被转换为音频信号,最终生成完整的语音。
流式设计
在流式音频和视频交互的场景中,初始数据包延迟是衡量系统性能的关键指标。延迟可能由以下因素导致:
- 多模态信息输入处理导致的延迟:处理多种模态(文本、音频、图像、视频)的输入需要时间和计算资源。
- 从接收到第一个文本输入到输出第一个语音标记之间的延迟:模型需要时间来处理输入并生成第一个语音标记。
- 将第一段语音转换为音频的延迟:生成的语音标记需要进一步处理才能转换为可播放的音频信号。
- 架构本身的固有延迟:模型的规模、计算量(FLOPs)等因素也会影响延迟。
为了降低这些延迟,Qwen2.5-Omni在算法和架构上进行了多项改进。
- 支持预填充分块预填充(Chunked-prefills)是现代推理框架中广泛采用的机制,用于提高处理效率。Qwen2.5-Omni通过以下方式支持这一机制:
- 音频编码器的分块注意力:传统的音频编码器通常对整个音频进行全局注意力处理,这在处理长音频时会导致较高的延迟。Qwen2.5-Omni将音频编码器的全局注意力改为每2秒为一个块的分块注意力。这样可以减少每次处理的数据量,从而降低延迟,减少处理时间。
- 视觉编码器的优化:视觉编码器使用Flash Attention实现高效训练和推理,并通过简单的MLP层将相邻的2×2标记合并为单个标记。补丁大小设置为14,这使得不同分辨率的图像可以打包为一个序列。这种合并操作减少了标记的数量,从而减少了计算量。
- 流式编解码生成为了实现音频的流式生成,尤其是长序列的流式生成,Qwen2.5-Omni提出了一种滑动窗口块注意力机制,限制当前标记仅能访问有限的上下文。具体实现如下:
滑动窗口块注意力机制:将DiT(Diffusion-based Inverse Text-to-Speech)模型的感受野限制为4个块,包括2个回溯块和1个前瞻块。这种限制使得模型在生成当前标记时,只能访问有限的上下文信息,从而减少了计算量和延迟。
分块生成:在解码过程中,将输入编码分组为块,输入编码通过Flow-Matching转换为梅尔频谱图,随后通过改进的BigVGAN将生成的梅尔频谱图重建为波形。

2、预训练
Qwen2.5-Omni的预训练目标是:
- 增强语义理解:通过多模态数据的训练,使模型能够更好地理解文本、音频、图像和视频中的语义信息。
- 提高泛化能力:通过多样化的数据和任务,使模型能够适应不同的应用场景和任务。
- 支持复杂长序列数据:通过长序列数据的训练,使模型能够处理复杂的多模态交互任务。
第一阶段:冻结LLM参数,训练视觉和音频编码器
目标:专注于训练视觉编码器和音频编码器,增强LLM内部的语义理解能力。
数据:使用大量音频-文本和图像-文本对数据。
方法:这一阶段,LLM的参数保持不变,只训练视觉和音频编码器。视觉编码器基于Qwen2.5-VL初始化,音频编码器基于Whisper-large-v3初始化。训练时,两个编码器在冻结的LLM上分别训练,都先训练各自的适配器,再训练编码器本身。这一基础训练对建立视觉-文本和音频-文本的核心关联与对齐至关重要。
第二阶段:解冻所有参数,全面训练
目标:通过更广泛的多模态数据进行更全面的训练,增强模型的多模态理解能力。
数据:
- 图像和视频相关数据:增加8000亿token。
- 音频相关数据:增加3000亿token。
- 视频-音频相关数据:增加1000亿token。
方法:在这一阶段,LLM、视觉编码器和音频编码器的所有参数都参与训练。引入更多混合多模态数据和多样化任务,增强听觉、视觉和文本信息之间的交互与深度理解。
第三阶段:长序列数据训练
目标:增强模型对复杂长序列数据的理解能力。
数据:使用32k序列长度的数据。
方法:在前两个阶段,最大token长度限制为8192,以提高训练效率。在这一阶段,引入长音频和长视频数据,将原始文本、音频、图像和视频数据扩展到32,768 token进行训练。通过长序列数据的训练,模型能够更好地处理复杂的多模态交互任务,如长视频理解和长音频生成。
3、后训练

- <|im_start|> 和 <|im_end|>:表示一个对话轮次的开始和结束。
- <|vision_start|> 和 <|vision_end|>:表示视频或图像输入的开始和结束,括号内是视频或图像的描述。
- user 和 assistant:分别表示用户和助手的角色,用户提出问题,助手提供回答。
Thinker
在后训练阶段,Thinker使用ChatML格式的指令跟随数据进行指令微调。具体来说:
- 数据集:包含纯文本对话数据、视觉模态对话数据、音频模态对话数据和混合模态对话数据。
- 目标:通过指令微调,使Thinker能够更好地理解和执行自然语言指令,生成准确的文本响应。
Talker
第一阶段:上下文延续训练
目标:训练Talker学习上下文延续,即根据上下文生成自然流畅的语音。
方法:使用下一个token预测任务,利用包含多模态上下文和语音响应的大规模对话数据集进行训练。Talker学习建立从语义表示到语音的单调映射,同时学习根据上下文表达具有多样化属性的语音,如韵律、情感和口音。
音色解耦技术:防止模型将特定声音与不常见的文本模式关联,提高语音生成的多样性和适应性。
第二阶段:强化学习(DPO)
目标:提高语音生成的稳定性,减少模型幻觉。
方法:使用DPO(Direct Preference Optimization)技术,通过强化学习优化语音生成。具体来说,对于每个带有参考语音的请求和响应文本对,构建一个包含三元组数据的数据集D,根据词错误率(WER)和标点停顿错误率对样本进行排序,选择奖励分数高的样本进行训练。

第三阶段:说话人微调
目标:使Talker能够采用特定声音并提高语音响应的自然度。
方法:在基础模型上进行说话人微调,使模型能够生成特定说话人的语音,提高语音的自然度和可控性。
4、X→文本评估
这一部分评估了Qwen2.5-Omni在理解各种多模态输入(文本、音频、图像和视频)并生成文本响应的能力。
文本→文本
评估集中在通用评估、数学与科学能力以及编程能力三个方面,使用了以下基准:
- 通用评估:MMLU-Pro、MMLU-redux、Livebench0803
- 数学与科学:GPQA、GSM8K、MATH
- 编程能力:HumanEval、MBPP、MultiPL-E、LiveCodeBench
结果:Qwen2.5-Omni在大多数基准测试中优于Qwen2-7B,展现了卓越的文本生成能力。

音频→文本
评估包括音频理解、音频推理和语音聊天三个方面,处理音频输入并生成文本响应的能力,使用了以下基准:
- 自动语音识别(ASR):Fleurs_zh、CommonVoice_en、CommonVoice_zh、CoVoST2_en-de、CoVoST2_zh-en
- 语音到文本翻译(S2TT):同上
- 语音实体识别(SER):Meld
- 人声分类(VSC):VocalSound
- 音乐理解:MusicCaps
- 音频推理:MMAU
- 语音聊天:VoiceBench
结果:Qwen2.5-Omni在音频理解任务上达到或超越了其他最先进方法的性能。此外,在VoiceBench上,Qwen2.5-Omni取得了74.12的平均分,显著超越了其他同类规模的音频语言模型和Omni模型。


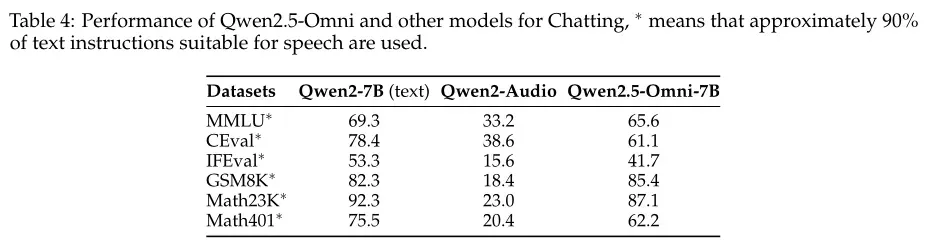
图像→文本
评估关注大学级问题、数学、通用视觉问答和OCR相关任务,使用了以下基准:
- 大学级问题:MMMU、MMMU-Pro
- 数学:MathVista、MathVision
- 通用视觉问答:MMBench-V1.1、MMVet、MMStar、MME、MuirBench、CRPE、RealWorldQA、MMERealWorld、MM-MT-Bench
- OCR相关任务:AI2D、TextVQA、DocVQA、ChartQA、OCRBench_v2
结果:Qwen2.5-Omni的表现与Qwen2.5-VL-7B相当,在多个基准测试中优于其他开源omni模型。

视频→文本
评估Qwen2.5-Omni在处理视频输入并生成文本响应的能力,使用了以下基准:Video-MME、MVBench、EgoSchema
结果:Qwen2.5-Omni在所有最先进的开源omni模型和GPT-4o-Mini上都表现优异,与Qwen2.5-VL-7B相比也取得了相当或更好的结果。

多模态→文本
评估Qwen2.5-Omni在处理多模态输入(结合文本、音频、图像和视频)并生成文本响应的能力,使用OmniBench基准,结果显示,Qwen2.5-Omni在OmniBench上取得了最先进的性能,大幅领先其他Omni模型。

5、X→语音评估
由于缺乏相关的标准评估方法,X→语音评估主要关注了两个方面:零样本语音生成(Zero-shot Speech Generation)和单说话人语音生成(Single-Speaker Speech Generation)。
零样本语音生成(Zero-shot Speech Generation)
零样本语音生成是指在没有针对特定说话人进行微调的情况下,模型能够生成语音的能力。这一部分的评估主要关注两个指标:
- 内容一致性(Content Consistency):通过词错误率(WER)来衡量生成语音与目标文本的一致性。
- 说话人相似度(Speaker Similarity):衡量生成语音与目标说话人的相似度。
评估方法:使用SEED数据集进行评估。将Qwen2.5-Omni与最先进的零样本TTS系统进行比较,包括Seed-TTSICL、Seed-TTSRL、MaskGCT、E2 TTS、F5-TTS、CosyVoice 2等。
结果显示,Qwen2.5-Omni在零样本语音生成任务上表现出色,通过上下文学习(ICL)和强化学习(RL)优化,显著提高了生成语音的内容一致性和说话人相似度。

单说话人语音生成(Single-Speaker Speech Generation)
单说话人语音生成是指在对特定说话人进行微调后,模型能够生成高质量语音的能力。这一部分的评估主要关注:
- 内容一致性(Content Consistency):通过词错误率(WER)来衡量生成语音与目标文本的一致性。
- 自然度(Naturalness):通过主观评估(如MOS评分)来衡量生成语音的自然度。
评估方法:使用SEED数据集进行评估。比较说话人微调前后的Qwen2.5-Omni模型以及人类录音。
结果显示,经过说话人微调的Qwen2.5-Omni在单说话人语音生成任务上表现出色,不仅在内容一致性上接近人类水平,而且在自然度上也达到了接近人类水平的性能。

6、总结
Qwen2.5-Omni的突破性进展标志着AI向"全能选手"时代迈出了关键一步,其技术实现和设计理念深刻反映了多模态大模型的三大发展趋势:
- 模态融合的深度突破通过Thinker-Talker架构的创新分工(Thinker专注语义理解,Talker专精语音生成),配合TMRoPE位置编码技术,模型实现了跨模态信息的毫秒级同步。这种"分工明确+一体化训练"的策略,使模型在同时处理视频帧(40ms/帧)和音频流时仍能保持时序一致性,解决了传统多模态模型"各自为政"的核心痛点。
- 交互范式的革命性升级模型在VoiceBench 74.12分的表现和1.42%的中文WER,证明了其实时语音交互已达实用水平。特别是32K长序列支持能力,使其可处理30分钟连续对话(如医疗问诊场景),配合滑动窗口DiT技术将端到端延迟降低40%,为"边说边想"的自然交互提供了技术基础。
- 技术落地的临界点突破从预训练阶段的渐进式解冻策略(先单模态适配器后全参数训练),到后训练阶段的三阶段语音优化(DPO强化学习使WER再降15%),形成了一套可复用的多模态训练范式。在OmniBench 56.13%的跨模态理解准确率,以及超越专业TTS系统的语音生成质量(NMOS 4.51/5),标志着技术成熟度已达到商业化门槛。
这种技术演进正在重塑人机交互边界:当设备能同步理解用户展示的CT影像(MMBench 81.8%准确率)、实时翻译会议视频(CoVoST2 en-zh BLEU 30.2)、并给出带情感语调的分析报告(SEED相似度0.754),传统的"单一模态+分步处理"模式将被彻底颠覆。值得注意的是,该模型在保持7B参数规模下的高效表现,让我们对下一代AI产品充满了无限想象。


