本项目由复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员领导,博士生韩槿一,硕士生李廷云、熊程元、姜子上、王昕奕等同学共同参与完成。
GPT - 4o、Deepseek - R1 等高级模型已展现出令人惊叹的「深度思考」能力:理解上下文关联、拆解多步骤问题、甚至通过思维链(Chain - of - Thought)进行自我验证、自我反思等推理过程。
但是,多数主流模型仍在基础问题上犯错,复杂四则运算计算失误,简单「两个小数比大小」出错、甚至连数清楚 strawberry 里有几个「r」都能翻车……即使提示像 R1 这样具备深度思考能力的大模型也要消耗大量的 token 才能勉强答对。
合适的工具调用能够拓展大模型的能力边界,但现有工具调用方式将大模型限制在预设的工具使用框架内,更像是一个被动的「提线木偶」,而非真正具备主动性的智能体。主要体现在以下几个方面:
浅层模仿而非深度理解:SFT 只是学会了特定场景下工具调用的表面模式,而非真正理解工具的功能边界、适用场景和内部工作机制
上下文依赖性强:基于 Prompt 的工具调用方法高度依赖于提示的精确性和完整性。一旦用户描述模糊或提示设计不当,模型就无法正确选择和使用工具
工具组合能力受限:当需要多个工具协同解决复杂问题时,现有方法难以支持模型进行灵活的工具组合
复旦大学知识工场实验室团队在开源项目 SimpleGRPO 中开源实现了大模型自主工具调用机制,通过引入大模型的深度思考能力,从根本上重构了大模型工具调用的范式。该技术使大模型实现了从被动执行的「提线木偶」到具备自主决策能力的智能体的根本跃迁。
项目开源地址为:https://github.com/lsdefine/simple_GRPO/tree/main/Auto_Program
为什么大模型需要自主调用工具的能力?
深度整合:大模型不仅是工具的「操控者」,而是能在推理过程中深度理解工具的功能,知道什么时候、如何使用工具才能更高效地解决问题。
动态调整:每次调用工具后,模型会根据新获得的信息自动调整思路,不断改进解决方案,让每一次思考都更精确。
连续性与灵活性:不同于传统的单次工具调用,自主工具调用能力可以使得模型能够在复杂任务中多次调用工具,通过连续的交互获取最佳答案。
创新组合:当一个工具无法完成任务时,模型能创新性地将多个工具结合起来,解决更为复杂的挑战。

表. 一般模型和融入思考进行自主工具调用的模型在工具调用上的能力表现的差异
如何实现大模型的工具自主调用?
我们使用强化学习算法给 LLM 装上「决策中枢」,实现两种神仙模式:
方案 1【边想边干】:LLM 思考到一半突然写代码辅助解决 → 编译器运行 → 继续思考完成后续的推理
当大模型在生成推理或解决问题的过程中,意识到某些步骤需要借助编程工具(如 Python)来完成时,它会直接生成相应的代码片段,并通过编译器执行这些代码,执行结果会被捕获并作为输入重新融入到大模型的推理过程中。
这种即时反馈机制使得模型能够动态调整后续的生成内容。这种方式类似于人类在解决问题时,发现某个计算或分析任务复杂到需要用程序来辅助,便动手编写代码并运行结果。
方案 2【专业分工】:LLM 负责提需求,直接说「我需要计算 38 和 16 的最小公倍数」,专属代码小弟秒速响应!强强联手更精准!
生成模型在推理过程中,当遇到需要编程工具协助的任务时,会明确描述出需求。例如,「我需要计算一组数据的标准差」或「请帮我实现一个排序算法」。这种需求描述通常以自然语言的形式表达,清晰且易于理解。接收到需求后,专门的代码生成模型会根据描述生成对应的 Python 代码。
该模型经过大量代码训练,擅长将自然语言需求转化为准确的代码实现。生成的代码通过编译器执行,执行结果被返回给生成模型。生成模型根据结果调整后续推理路径,确保整个过程连贯一致。
大模型边思考边行动
大模型自主调用 Python 命令行
我们首先在简单数学题上验证模型能否通过强化学习学会调用工具计算器来辅助解决问题,并观察其泛化性。我们设定模型可在回答中通过「>>>」调用 Python 命令行,检测到需要调用 python 程序时,编译执行并将代码运行结果插入到先前的生成过程中。以 Qwen2.5 - 7B 为基础模型,在 GSM8K 上训练。
模型执行复杂运算时会自主调用命令行来计算

模型在训练时只接触数学题,但推理时能自主泛化到其他问题上
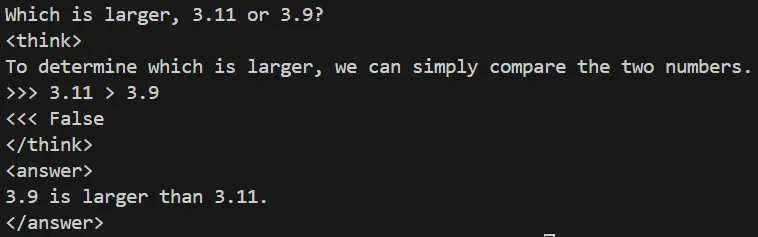
3.11 和 3.9 谁大?
以前:瞎蒙(甚至理直气壮答错)
现在:秒写代码 print(3.11 > 3.9),输出 False,铁证如山!
strawberry 有几个「r」?
以前:靠概率硬猜(结果常漏数)
现在:直接上代码 "strawberry".count('r'),精准输出 3!

模型调用 Python 程序
面对更难的问题时,我们发现命令行难以发挥作用。例如,模型使用 Python 来解方程时,需要导入相应的包,如果使用互相独立的命令行难以完成,将多个命令行一起执行则模型容易在格式和代码编写上出错。因此,我们尝试让模型自己写整段的 python 程序。
基础模型:Qwen2.5 - Math - 7B - Base
算法:Reinforce++ • 数据集:MATH level3 - 5 上进行训练
训练重要参数设置:temperature:0;学习率:4e - 7;batch_size: 32;
奖励设置:回答中包含 \boxed{} 且其中答案正确,则奖励为 1,否则奖励为 0
训练结果如下:

复杂一元三次方程求解借助编程解决
模型内心 OS:「这题手算会崩,看我召唤 Python!」

大模型主动提出调用工具需求
实验细节
1、训练数据集构建:
从 MATH、Numina、OpenThoughts 中筛选训练问题时按照以下原则:
使用 Qwen2.5 - 7B - Base 对问题生成多个答案,过滤掉对模型而言较为简单的题(正确率为 100%)
过滤掉选择题、概念题等没有标准答案的问题
2、测试数据集: 以 GSM8K 题目为原型,将其中的数值替换成超大(9~11 位)或者更加复杂(小数)的数值。
数据集开源地址:https://huggingface.co/datasets/JinyiHan/big-value-gsm
3、算法:GRPO
4、训练技巧:
奖励设置:我们注重对格式的奖惩,这样可以保证在模型训练前期能快速学习到格式,格式准确率能够逐渐达到 95% 以上;从而在后期训练阶段模型能够专注于提升回答的准确率。

课程学习:按照模型正确回答的概率从大到小进行排列
避免 GRPO 同组得分同质化:在训练过程中,得分完全相同的样本直接过滤掉
5、模型选择:
生成模型:Qwen2.5 - 7B - Instruct
代码模型:Qwen2.5 - 7B - Instruct
实验结果

模型反复多次提需求调用工具
以前:硬着头皮硬算,强行编答案
现在:思考后主动使用工具辅助解决


其他有意思的观察:
模型能够根据代码编译结果能进一步反思
当模型编写的 python 代码出现编译报错、没有输出或运行超时:
以前:出现错误后,后续生成的内容全部出错
现在:模型会根据报错信息继续调整策略

自主调用工具的能力能在未见的任务上进行泛化
以前:特定领域微调后并不会迁移到未见任务上
现在:掌握工具后可以在其他领域灵活使用
case1: Knight & Knave (Logic - RL)

case2: CountDown

解锁新能力,使用 python 来验证生成答案的正确性

总结
我们探索了结合大模型的深度思考能力提升大模型自主工具调用的能力的两种方式,包括让大模型边思考边行动、以及让大模型提出调用工具的需求。
我们发现,通过强化学习的训练方式,边想边干和专业分工两种方式都能够使大模型灵活、自主地调用工具,并在生成过程中多次调用工具,将工具调用的结果无缝融入后续的推理与决策流程中。
更重要的是,这种自主工具调用能力展现出强大的泛化性,能够成功应用于完全未见过的任务场景,表现出令人惊叹的潜力。
这一研究成果为未来大模型深度思考能力的实际应用提供了重要的参考价值和技术基础。我们计划在不久后发布相关技术报告或论文,对这些方法进行更详细的阐述和讨论,敬请期待。


