
今天来看一篇经典的视觉表征学习的方法EVA,来自智源研究院发表在2023年CVPR的一篇工作。

项目地址:https://github.com/baaivision/EVA
研究动机:自然语言处理(NLP)领域通过扩展预训练语言模型(PLMs)取得了革命性的成功,作者希望将这种成功从语言领域转移到视觉领域,即扩展一个视觉中心的基础模型,以便于视觉和多模态下游任务。
另外,视觉模型预训练和扩展的方法主要依赖于监督或弱监督训练,需要数百万个(通常是不可公开访问的)标注数据。作者指出,自然图像是原始且信息稀疏的,理想的视觉预训练任务需要抽象出低级几何结构信息和高级语义信息,而像素级恢复任务很难捕获这些信息。因此提出EVA。

CLIP 模型输入为完整的图像,而 EVA 模型的输入为有遮盖的图像,训练过程是让 EVA 模型掩码部分的输出去重构 CLIP 模型对应位置的输出,从而以简单高效的方式让 EVA 模型同时拥有了最强语义学习 CLIP 的能力和最强几何结构学习 MIM 的能力。
01、MIM任务
为了找到一个合适的MIM预训练任务,本文对比了两种方法:
(i) 恢复被掩盖的标记化语义视觉特征,(ii) 从强大的预训练表示中进行特征蒸馏。这两种方法都利用了预训练的图像-文本对齐视觉特征,即CLIP视觉特征。
EVA分别验证了MIM中的tokenize和Feature Distillation中的蒸馏方式都不是必要的。不用toeknize和蒸馏的效果对比如下图所示,图a和b中第一行都是clip作为teacher模型在下游任务上fintune的效果,最后一行都是EVA模型的效果。区别在于图a的二三行使用了tokenize的方式训练了300和1600epoch,但效果都不如没有使用tokenize训练800epoch的EVA,证明了tokenize的方式并不必要;图b中二三行使用Feature Distillation的蒸馏方式训练了300和800epoch,验证了蒸馏时间变长,并没有带来更大的收益,并且也不如同样训练800epoch的EVA,证明了Feature Distillation的蒸馏方式不是必要的。

最后得出结论:
- 选择MIM任务:选择了直接回归被掩码的CLIP视觉特征作为MIM预训练任务,因为它能够同时从图像-文本对比学习的高级语义抽象和掩码图像建模中的几何与结构的良好捕捉中受益。
- 预训练任务的优势:这种预训练任务能够覆盖大多数视觉感知任务所需的信息,并且在大规模参数和未标记数据上具有良好的扩展性。
02、模型训练
架构配置(Architecture):EVA是基于Vision Transformer(ViT)的模型,具有10亿参数。其架构设计参考了ViT巨型模型和BEiT-3的视觉编码器。在预训练阶段,EVA没有使用相对位置嵌入和层缩放技术。
预训练目标(Pre-training Objective)
- 掩码图像建模(MIM):EVA通过预测被掩盖的图像-文本对齐的视觉特征来进行预训练,这些特征是基于可见图像块的条件。这种方法结合了图像-文本对比学习的高级语义抽象和掩码图像建模中的几何结构信息。
- 输入掩码:输入图像块被[MASK]标记覆盖,采用块级掩码,掩码比率为40%。
- 目标特征:在EVA模型的预训练中,这些从OpenAI CLIP-L/14模型提取的特征被用作目标特征。EVA模型通过预测被掩盖(masked out)的图像部分对应的CLIP特征来进行训练。这意味着EVA模型的输入包括可见的图像块和被掩盖的图像块,而它的目标是预测那些被掩盖块的CLIP特征。
- 特征处理:EVA的输出特征首先被标准化,然后通过一个线性层投影到与CLIP特征相同的维度。使用负余弦相似度作为损失函数。
预训练数据(Pre-training Data):预训练EVA使用的数据集包括ImageNet-21K、CC12M、CC3M、Object365、COCO和ADE,总共约有2960万张图像的。
网络的整体架构比较简单,确实相对于MIM是非常简洁的结构:
- 输入: 一张图像,经过两次增广,分别作为teacher和student的输入
- tracher: 一个训练好的网络,可以是CLIP或者DINO
- student: 随机初始化的VIT模型或者swin transformer
- loss: 训练目标是让计算teacher网络输出的特征和strudent网络经过projector head后的特征的L1 loss。期望让student网络的特征和teacher网络的特征相似

论文的整体思路很简单,当然里面也有很多消融实验让蒸馏的效果尽可能好。例如和对比学习的方法中一样,student模型的输出增加了projector head;为了更好的对比不同teacher模型指导蒸馏的差异,将teacher输出的特征做了whitening处理将所有teacher模型的特征归一化到同一量级;VIT中采用相对位置编码,而不是原始的绝对位置编码。
03、实验结果
图像分类

图像分类上的结果如上图所示,最上面三行灰色的部分,模型参数量都在10亿以上,效果也是最好的,但使用了大量私有的数据集做训练。下面的结果除了BEIT外基本都在14M的IN-21K数据集上训练,但EVA在相同数据规模的情况下,参数量是最大的,且效果也是最好的。
不同数据集上的鲁棒性

视频动作识别

目标检测和实例分割

语义分割

对比语言-图像预训练
实验设置:使用预训练的EVA模型作为视觉编码器,并初始化一个语言编码器,例如OpenAI CLIP-L模型。采用对比学习来训练模型,使用大量的图像-文本对来提供正负样本。
通过对比语言-图像预训练,EVA模型在零样本分类任务上表现出色,这表明模型能够捕捉到丰富的视觉和语言特征,并有效地将它们关联起来。这种方法增强了EVA模型的多模态能力,使其不仅在纯视觉任务上表现出色,而且在涉及语言和视觉结合的任务上也具有强大的性能。
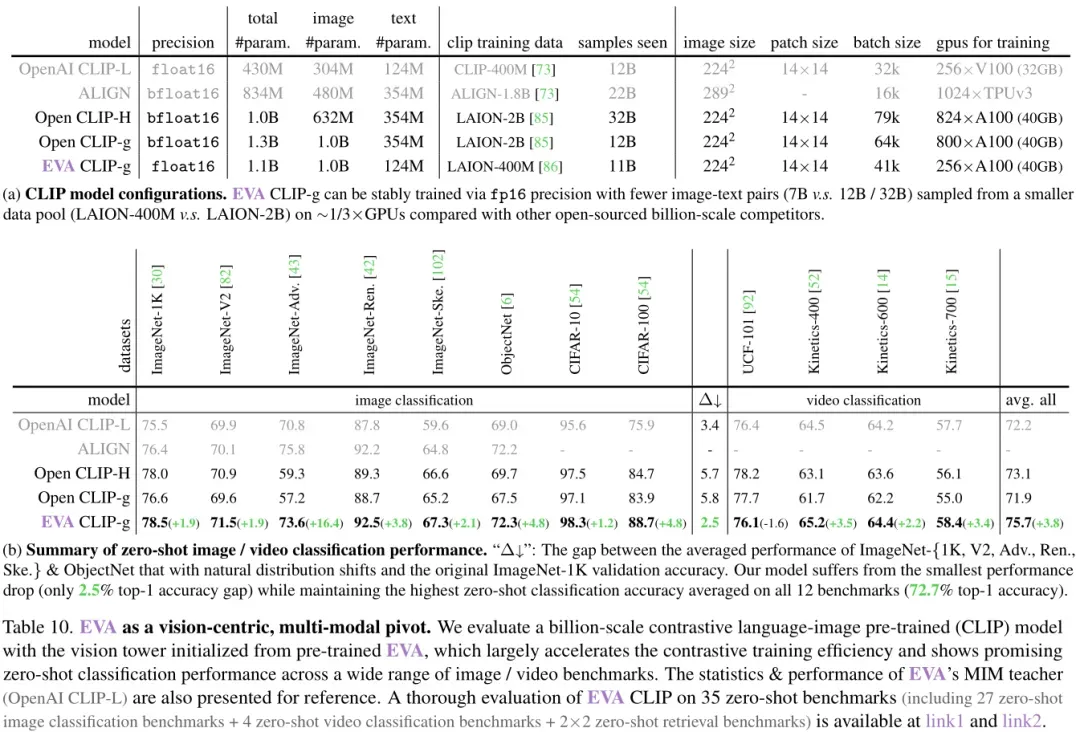
EVA-CLIP性能

EVA-CLIP模型在所有三个评估指标上都超过了之前的最佳模型,表明EVA-CLIP模型在自监督学习(SSL)领域具有显著的性能优势,特别是在微调和线性探测设置中,EVA-CLIP模型展现了其强大的迁移学习能力和适应性。
04、总结
很有意思的一篇文章,最近也了解了部分蒸馏学习的内容。蒸馏方向的论文,基本都是为了让一个小的student网络在不损失太多性能的前提下,学习到大的teacher网络的特征。 而在大模型时代,EVA探索了student网络能达到的规模上限,并且在测试集上效果略微超过了teacher网络。 为什么EVA蒸馏后的网络会比teacher网络有更好的效果呢?个人感觉是CLIP确实足够强大,而且EVA中student网络的MIM训练方式足够的好。具体而言CLIP在4亿的图文对上做了预训练,输出的图像特征和语言的特征做了对齐,是一种高维的语义信息,而VIT作为一个backbone,更利于提取到低维的结构特征,并且MIM的方式迫使VIT学习遮挡不变的特征,最终的特征具有了很好的鲁棒性。
对于EVA和EVA-CLIP,
- EVA:主要是一个视觉表示学习模型,专注于通过掩码图像建模(MIM)任务来学习强大的视觉特征。EVA的目标是生成能够有效捕捉图像内容的视觉表示,通过MIM任务学习到的视觉特征可以用于各种下游视觉任务,如图像分类、目标检测和语义分割。
- EVA-CLIP:是一个视觉-语言模型,旨在通过联合训练图像和文本数据来学习图像和文本之间的对齐关系。EVA-CLIP不仅学习图像特征,还学习这些特征与相应文本描述之间的关联,从而支持跨模态任务,如零样本图像分类、图像-文本检索以及支撑多模态任务。


