DeepSeek本地部署
前段时间DeepSeek震惊了全世界
不容易啊终于国内有了自己的精品
 图片
图片
但访问过程中频繁的 “服务器繁忙”,也让很多人尝而不得作为技术人员都在考虑如何充分利用开源的价值
让我们的程序也能借船出海搭上AI的快车,那么问题来了。如果我需要本地部署一个大模型需要什么配置的电脑呢?
显卡、显存怎么选配
模型的大小,决定了对硬件的需求以 DeepSeek-R1 为例1.5b、7b、32b、70b、671b 之间差距非常大
 图片
图片
很多人埋怨说:我的大模型就是个“人工智障”但你得反过来检视一下是不是用的模型参数太少了?
我们谈论A模型比B模型强大前提都是在同一个体量上拿 7b 模型 对比 405b 模型本身就不是一个级别体量的。
官方给了一个模型版本和配置的对应表:
如下:
参数量 | FP16 显存占用 | INT8 显存占用 | INT4 显存占用 |
1.5B | 3.0GB | 1.5GB | 0.75GB |
7B | 14.0GB | 7.0GB | 3.5GB |
8B | 16.0GB | 8.0GB | 4.0GB |
14B | 28.0GB | 14.0GB | 7.0GB |
32B | 64.0GB | 32.0GB | 16.0GB |
70B | 140.0GB | 70.0GB | 35.0GB |
671B | 1342.0GB | 671.0GB | 335.5GB |
比较直观是吧!前几天看到梁斌博士自己搭建了一个满血版DeepSeek 671b 最强模型花了多少钱呢?
配置如下:
复制CPU
AMD EPYC 9534
64核 128线程,2.5 GHz
一共 2块CPU 共128核
GPU
AMD MI300X
192 G
一共 8块GPU 共 1536 G 显存
内存
1526 G效果如下:
 图片
图片
这么一台服务器下来250万打底,还只是AMD的配置。毕竟 MI300 系列还是数据高性价比的产品换成 NVEDIA 的 H100 或者 A100价格至少上升 50%
普通使用需要什么配置
我们大部分人都不追求极限你们大佬用 671b 的我用个 7b 或者 32b 的就差不多了,但要如何计算配置
网上有各种各样的教材需要你理解 int8、fp16、float32 等等专业术语和公式。
 图片
图片
最简单的方法
直接抄我的答案:用 参数量 ✖️ 系数 即可。常见的有int4 代表4位 系数0.5, int8 代表 8位 系数为1fp16 代表16位 系数为2, float32 代表 32位 系数为4。
怎么看系数?如果我们是通过ollama下载的模型,打开下载页。
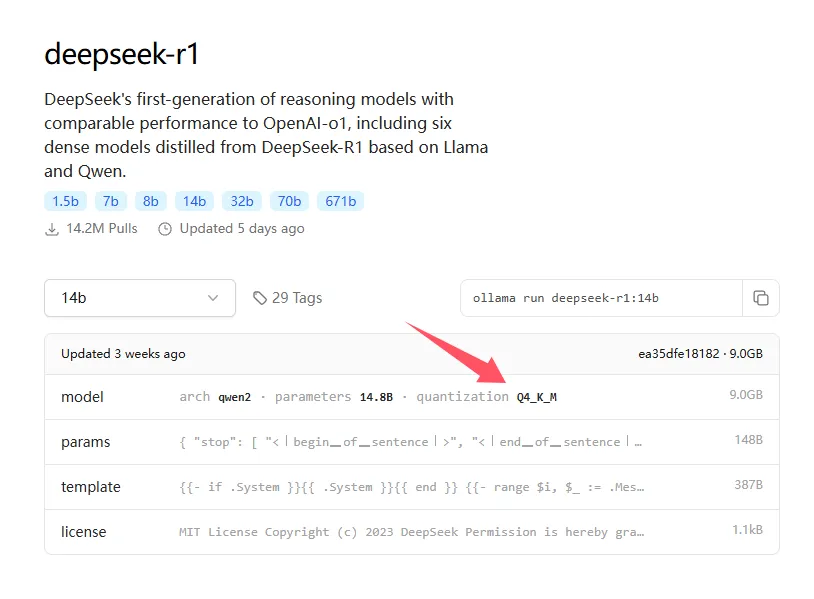 图片
图片
在 model 栏目会写一个参数:
复制quantization Q4_K_M
Q4 代表4位量化版本可以对标 int4,实际略高于 int4如果按 int4 的系数取 0.5,这里可以估算在 0.7 ~ 0.8 左右,如果估算 DeepSeek 的 Q4 量化版本型数据推理以及10个线程的并发请求我们系数取 0.8所以比如 计算 DeepSeek 14b 版本默认 fp16则显存需求为 14 ✖️ 0.8 = 11.2 G。
在满足显存的同时内存用量最好为显存的2倍用于加载模型和计算缓冲以下给出几个计算好的显存数值,都是以 DeepSeek-R1 Q4量化版 为例的最低配置。
参数量 | 显存 |
671B | 536 GB |
70B | 56 GB |
14B | 11.2 GB |
7B | 5.6 GB |
1.5B | 1.2 GB |
所以哪怕我们就是个普通的电脑跑个乞丐版 1.5b 通常问题不大,需要注意这里做了减法只包含基础运行和1个线程本地调用,如果需要更多访问推理请适当增加系数。
当然我给的方法只是粗算:
可以进入 https://huggingface.co/spaces/hf-accelerate/model-memory-usage
这个网站有个在线计算器,如图:
 图片
图片
只要提供各项参数即可计算出配置要求需要的朋友们可以自己尝试一下。


