论如何在技术圈争论中一句话噎到对方:
哥们,是我创造了第一个大语言模型。

发言者Jeremy Howard为澳大利亚昆士兰大学名誉教授、曾任Kaggle创始总裁和首席科学家,现answer.ai与fast.ai创始人,。

事情的起因是有人质疑他最近的项目llms.txt在帮助大模型爬取互联网信息上并没太大作用,从而引发了这段争论,迅速引起众人围观。
闻讯而来的“赛博考古学家们”一番考据之后,发现第一个大语言模型这个说法还真有理有据:
2018年初,Jeremy Howard发表的论文ULMFiT,使用非监督预训练-微调范式达到当时NLP领域的SOTA。

甚至GPT-1的一作Alec Radford,在发表GPT-1时也公开承认过ULMFiT是灵感来源之一。

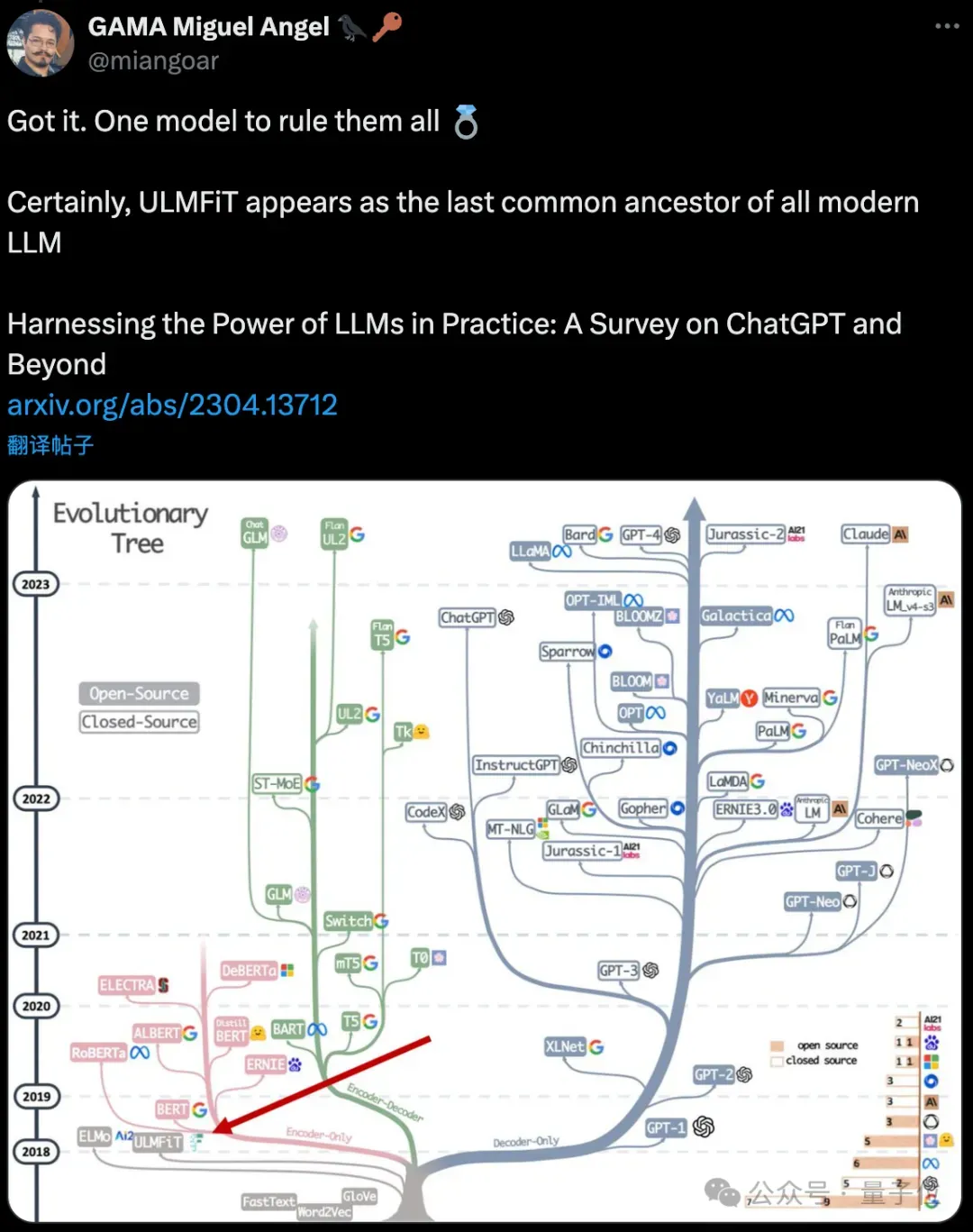
有人搬出综述论文,指出从“遗传学”视角看,ULMFiT是所有现代大模型“最后的共同祖先”。
还有好事者软件工程师Jonathon Belotti,专门写了一篇完整考据《谁才是第一个大语言模型》

大语言模型起源考据
首先来介绍一下ULMFiT这篇论文,入选ACL 2018:
提出有效迁移学习方法,可应用于NLP领域的任何任务,并介绍了微调语言模型的关键技术,在六个文本分类任务上的表现明显优于当时的SOTA方法,在大多数数据集上将错误率降低了18-24%。此外,仅使用100个带标签的示例,它的性能就与在100倍以上数据上从头开始训练的模型性能相当。

那么ULMFit算不算第一个大语言模型呢?Jonathon Belotti考据遵循这样的思路:
首先找一个大家都公认肯定算大语言模型的成果,GPT-1肯定符合这个标准。

再从GPT-1和后续GPT-2、GPT-3中提取一个模型成为成为大语言模型的标准:
- 首先要是一个语言模型,根据输入预测人类书面语言的组成部分,不一定是单词,而是token
- 核心方法是自监督训练,数据集是未标记的文本,与此前特定于任务的数据集有很大不同
- 模型的行为是预测下一个token
- 能适应新的任务:不需要架构修改,就有few-shot甚至one-shot能力
- 通用性:可以先进的性能执行各种文本任务,包括分类、问答、解析等
接下来分析GPT-1引用的几个重要模型:原版Transformer,CoVe,ELMo和ULMFiT。

Transformer虽然是现代主流大模型的架构基础,但原版只用于机器翻译任务,还不够通用。同时非Transformer架构如LSTM、Mamba甚至Diffusion也可被视作大型语言模型。
CoVE提出了语境化词向量,是迁移学习领域的一项重要创新,但它通过监督学习训练(英语翻译德语)创建向量,不符合自监督学习的条件。
ELMo使用了自监督预训练和监督微调范式,但在few-shot能力上还差点意思。
总之在作者Jonathon Belotti看来,CoVE和ELMo都还没达到大语言模型的门槛。
最后再来看ULMFiT,其名字代表在文本分类任务微调的通用语言模型(Universal Language Model Fine-tuning for Text Classification)。
它是一个在WikiText数据上自监督训练的LSTM模型,能够以低成本适应新任务,无需更改架构即可执行大量文本分类任务,且达到当时的SOTA性能。
与GPT-1相比,只差在微调不够方便,以及应用任务的广度。

GPT-1论文原文中,也指出“最接近我们工作的”就是ULMFiT与谷歌的半监督序列学习(Semi-supervised Sequence Learning)了。
GPT-1论文还声称,把LSTM换成Transformer后能拓展预训练模型的预测能力,比ULMFit任务适应性更高。

考据者Jonathon Belotti最后总结到:
成为第一重要么?我认为有一点重要。软件行业和学术界尊重其创始人,我们都是开源社区中构建开拓智域文化(homesteads the noosphere)的一部分。
而Jeremy Howard本人对此的后续回应是我们创造了第一个“通用语言模型”,但后续论文没有沿用,反而创造了“大型语言模型”这个新术语。

苹果工程师Nathan Lawrence认为,虽然今天大家对谁是第一个LLM可能存在争议,但最终大家都会把ULMFiT视为一个转折点。
当时即使我这样的怀疑论者,也快开始意识到大规模通用训练将成为NLP的未来。

也有人建议Jeremy Howard以后说ULMFit是第一个“通用预训练模型”。
“我发明了ChatGPT中的GP”,这句话说起来也很酷,一点也不夸张。
ULMFithttps://arxiv.org/abs/1801.06146
GPT-1https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf


